

成長型與價值型財報數據相關性全解析
2025 Dec 19 體驗與心得
以下文章為個人研究與實作紀錄,目的在於分享一套「如何用數據驗證成長型與價值型投資邏輯」的方法論,而非提供任何投資建議。
一、研究動機:用數據回頭檢驗十多年投資經驗
在價值投資領域打滾十多年後,愈來愈清楚一件事:投資經驗很重要,但經驗必須被反覆驗證。
近期我重新檢視自己長期奉行的價值型與成長型選股邏輯,決定嘗試用系統化數據與程式化方法,回頭拆分這些看似模糊的相關性的統計基礎。
這也是為什麼,一直以來我投入大量時間撰寫程式,將過往難以人工處理的大量財報資料,轉化為可分析、可驗證的結構化數據。
二、資料結構:1908 檔股票 × 8 季 × 68 項財報參數
本次分析的資料範圍如下:
-
樣本數:1908 檔上市櫃股票
-
時間維度:近兩年,共 8 季
-
財報參數:68 項(涵蓋獲利、成長、現金流、資本結構等)
為了讓不同尺度、不同單位的數據能夠彼此比較,我先對所有參數進行標準化與重整,並統一轉換為單一數值,主要分為三種類型:
-
趨勢型指標:8 季數據的「斜率 ÷ 平均值」,用來衡量中期變化方向
-
穩定度指標:8 季「平均值 ÷ 標準差」,衡量波動程度
-
近期值指標:最近一季的單一數值
最終,所有處理完成的數據被彙整為一張 CSV 檔,整個流程在程式完成後,產生數據時間不到 30 分鐘。
三、方法核心:監督式學習找出「真正有用」的參數
接下來的關鍵步驟,是利用 Python 中既有的機器學習模組,進行監督式學習(Supervised Learning)。
目標很單純:
在控制其他變數的情況下,找出哪些財報參數,對股價漲跌具有實質解釋力。
模型訓練完成後,我可以取得每一個財報參數對「股價報酬」的相對權重,並進一步回推:
-
這些權重是否呼應我們熟悉的成長型投資邏輯?
-
是否存在被長期忽略、但實際上很關鍵的指標?
這一步,本質上並不是為了「預測未來」,而是驗證既有投資模型的合理性。
四、重要修正:剔除邏輯上必然相關的參數
在初步結果中,我發現一個明顯問題。
例如:
-
本益比(Price / Earnings)
-
殖利率(Dividend / Price)
-
淨值比(Price / Book)
這類直接包含股價(Price)**的指標,在回歸中與股價漲跌「高度相關」是必然結果,但這樣的相關性並不具備研究價值。
因此,我刻意將這些在邏輯上已知會高度相關的參數剔除,重新訓練模型,只保留:
-
權重顯著(權重 > 1)
-
且通過皮爾森相關性檢定的參數
這樣得到的結果,才比較接近「結構性特徵」,而非參數自我解釋。
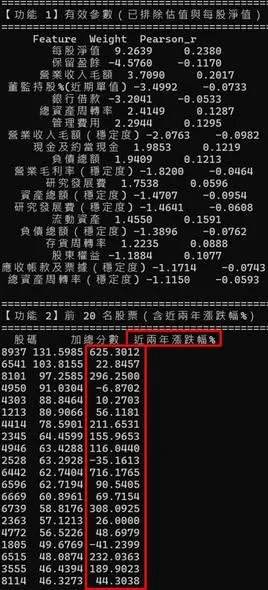
五、回推驗證:用權重反選股票,看結果說話
在新的權重條件下,我將這些參數重新套回 1908 檔股票,計算綜合得分,並選出得分最高的前 20 名股票,再回頭檢視:
-
這些股票在近兩年間的實際股價表現
必須誠實說明:
這個過程在時間上存在「已知結果再回看題目」的偏誤,因此並不嚴謹,也不符合純統計學的標準流程。
但投資從來不是一門純科學,它只能應用科學,而無法完全科學化。
即便如此,回推結果顯示,這組模型確實篩選出了具有明顯成長股特性的股票組合,而且使用的是「兩年八季的趨勢資料」,而非僅單一季度的短期數據。
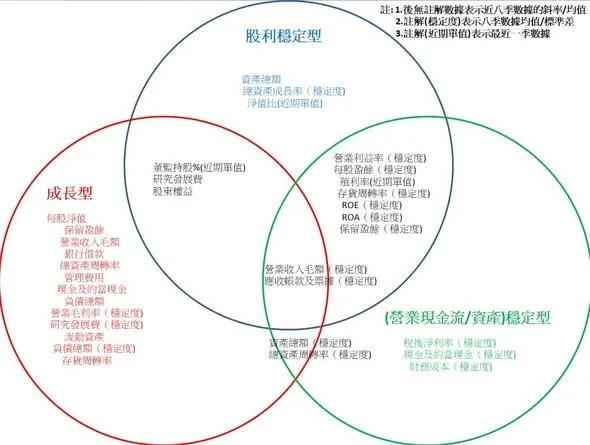
六、下一步:正式拆分成長型與價值型核心參數
完成成長型分析後,下一階段我將專注於價值型股票,預計重點放在:
-
股利穩定度
-
營業現金流 / 資產的長期穩定性
理論上,最終可以得到三組關鍵結論:
-
成長型股票的核心財報參數
-
價值型股票的核心財報參數
-
同時適用於兩者的共通指標
這將有助於更清楚地區分兩種投資策略在「價格容忍度」與「持有邏輯」上的本質差異。
七、投資不是天賦比拚,而是資源配置的競賽
市場待得愈久,愈能體會沒有什麼是「一定會贏」的。
搶速度、拚靈感、拼消息,我自知並非強項;那就用程式補反應、用時間換勝率、用紀律對抗波動。
正如巴菲特所說:
「如果你已經在牌桌上玩了半小時,卻仍然不知道誰是待宰羔羊,那麼你就是那一個。」
理解自己的優勢,並據此設計適合自己的投資戰場,才是長期存活的關鍵。
八、資料分享與風險聲明
本次分析所使用的權重結果,已整理於公開試算表中(含成長型篩選結果)。
https://docs.google.com/spreadsheets/d/14iB5i4poYc9NKMMw1gdhmkTc9EeSa6FGQpa2F1lfQkg/edit?usp=sharing
若有研究者希望進一步使用這些權重建構自己的模型,歡迎私下交流;即使直接取用,也無妨。
唯一需要再次強調的是:
本文僅為研究與方法分享,不構成任何投資建議,所有投資風險請自行評估並承擔。
持續研究,持續修正,繼續前進。
相關文章



大數據投資週報2025/01/17
在上週的台股表現中,類股漲幅榜前三由 塑膠類指數(漲幅14.3%)、油電燃氣類指數(漲幅11.5%)、玻璃陶瓷類指數(漲幅6.7%)領銜,展現明顯的資金輪動跡象。特別是塑膠類指數在連續兩週表現最弱後,本週逆襲成為漲幅榜首;與此同時,曾在上週表現亮眼的其他電子類股卻急速下挫,淪為本週跌幅冠軍。此類股間強弱互調的現象,似乎顯示市場資金從高風險的科技股轉移至較保守的產業,顯露防禦性投資情緒抬頭。而對比上週加權指數的僅0.6%漲幅,產業輪動效應更加明顯。
- 2025 Jan 17



如想留言評分,請先 登入會員!